

KMWorld 2018: Knowledge Management in the Age of AI, IoT and XR
On November 7, 2018, I gave a talk at KMWorld 2018 on knowledge management in the age of artificial intelligence, the Internet of Things (IoT) and XR (AR/VR/Mixed reality). This is a post based on that talk. It is not a transcript.
Introduction
When it comes to the discussion of AI for knowledge management, much of the dialog focuses on how AI augments many of the tedious, detailed content analysis work associated with making knowledge more accessible. Key areas include content tagging, summarization and recommendation. Microsoft is making big strides with SharePoint 365 to integrate features like content discovery through tools like Delve. Delve uses the Microsoft knowledge graph to understand the relationships between people, projects, content and communications.
While some content discovery derives from the passive use of systems (unsupervised training), most AI requires supervised training. Large data sets identified, coded and organized for effective use by the learning algorithms. Rather than supplanting knowledge managers, this transitional period in AI and IoT requires more knowledge discovery, even while it reduced the tedium. Significant new knowledge will be required to make sense of data, design effective IoT environments and figure out how to add spacial knowledge to experiences that don’t typically require it (beyond innate human abilities).
The roles for AI, the roles for people
AI will play several roles, including acting as a proxy for people and in some cases, as a replacement. However, AI currently focuses primarily on assistance. This means that AI does the bidding of the human. With the advent of technology like chatbots, AI begins to act as a proxy. People setup scenarios and expectations, in some cases machine learning mines logs. Customers services get served up without people, until a path outside the logic indicates a person is needed. While people continue to refine the customer service experience and gain knowledge about customers and products, the AI acts on their behalf for routine activities.
Will, or does AI replace people? The answer here is yes and no. If you look at areas with highly reproducible activity, such as the monitoring of equipment and interpretation of data coming in from sensors, then yes, there will likely be a replacement for many field technicians who inspect and monitor equipment. But the architecture of that solution will create the need for new knowledge. We’ll get back to that in a bit.
Some of the work of AI, such as predictive marketing, wasn’t possible before. Sure, a personal shopper could recommend purchases once he or she got to know a client, but that was a very rare relationship. Personal shopping is as much about the camaraderie and collaboration as it is about the recommendation. What AI does is expand the executable part of that relationship to many more people. Personal shoppers remain, but more people now receive purchase recommendations that leverage knowledge of past shopping to suggest future purchases from AI, or at least from algorithms.
Some jobs, like tagging unstructured content with metadata may be near its end, but that is one of those jobs that offered an obscure career path and attracted very few enthusiasts. That AI can read content, extract features, define tags and categories and automatically associate those with the content augments and accelerates the use of knowledge, leading to more value from existing content. That a few people get displaced may be of significance to those employees, but AI presents as an insurmountable competitor when it comes to limited scope cognitive tasks for which data exists to create training sets. Therefore areas like the redaction of content from a large corpus of similarly structured documents, or those that share concepts, become a sweet spot for the application of AI.
With that said, the knowledge components shift in an application like redaction. While the systems clearly require the knowledge for how to manually react the documents, what doesn’t exist yet in most organizations is the knowledge for how to build the training sets, or how to evaluate the software that would perform such duties. Organizations need to build new expertise in order to effectively manage AI, IoT and XR investments.
Another example of the need for new expertise comes in the form of Amazon’s Alexa. The Alexa app proves adept at core questions, but the model gets challenged as others build skills. People need to remember what skills they have enabled, and the expected syntax for a dialog with those skills.
More importantly, developers need knowledge about how to build conversations interfaces, which applications perform best in voice conversations and how to encode conversation in a way that seems natural. Amazon provides a number of tools, as well as guidance from its own experience, but because of the complexity of the knowledge domain writ large, each app much tackle the knowledge related to its domain. Organizations that build this expertise will create a competitive advantage.
AI requires new skills and new knowledge. This worked example of a manufacturing predictive analytics vision offers insight into several places where knowledge work changes or increases based on the adoption of new technology.

A worked example: AI, IoT and predictive analytics
The goal for maintenance in manufacturing firms or other facilities with complex equipment and the need for near always-on operations is to maintain its equipment in the smallest window possible.

In manufacturing most machines still follow a relatively simple preventative maintenance schedule. When the machine needs to be maintained, it gets taken offline, torn down or tweaked, and then put back into service. Sometimes this can take hours. And because of the expense of large equipment, most facilities don’t purchase redundant systems to account for production outages during maintenance.
The dream for AI to create a small window that optimizes the for production needs, quality (give enough time to do the maintenance correctly), the inventory of available maintenance parts should a replacement part be required, and labor. Narrow the window so maintenance of equipment has the least impact on production, and therefore on the business and its ability to deliver goods or to house its occupants.
A data/#AI challenge: We don’t know what to throw away and what to keep. Sensor/predictive maintenance case study offered by @DanielWRasmus at #KMWorld. pic.twitter.com/ZQz5Rfe4wJ
— Seth Grimes (@SethGrimes) November 6, 2018
Several new areas emerge as knowledge domains when the traditional clipboard reporting, human sythesis and preventative maintence gets replace by the data assoicated with IoT and interpretation available through AI. These include IoT planning, data integration, data correlation to symptoms, causes and remidiations.
For IoT planning the task is straightforward: which devices to place where and where does their data go. As straightforward as that may be, it includes a number of subdomains, such as sensor vendor knowledge, IoT sensor placement and coverage, as well as data formats coming from the sensors.
Imagine a machine on a factory floor. It usually has a maintenance technician walk up to it every few weeks, apply a probe, take a reading, place a hand on the motor assembly and conduct a visual inspection. The technician jots down some notes on a clipboard, and they usually get entered into a computerized maintenance management system (CMMS).
The vision for maintenance revolves around the combination of IoT and AI. Sensors provide a wide range of data that act communicate the health indicators of the equipment. These sensors can include:
- Smoke and gas sensors
- Humidity sensors
- Liquid sensors
- Radiation sensors
- Thermal sensors
- Position sensors
- Sound/vibration sensors
- Strain sensors
- Level sensors
- Pressure sensors
In addition, cameras provide for a general visual sensor that can sense movement or provide access to environmental conditions, such as puddles from leaks). Placing these sensors requires a plan and that’s where KM professionals can work with maintenance teams to understand the processes for optimizing sensor types, placement and monitoring. For organizations that typically rely on preventative maintenance, it may be some time before they have enough data to understand what the sensors are telling them, what it means and what they should do about it.
Given the goal of narrowing the maintenance window and the often high-cost of equipment, teams will not most likely not be able to run tests to see how well a particular configuration of sensors meets their needs, at least not in the timeframes required to reflect value.
Some might ask, what about simulations? Simulations would be great if they included a fully functional machine and a way to precisely mimic sensor configurations. This will probably be possible in the future, but people need to build the out the simulations along with a variety of 3rd-party sensors to integrate. Not only is this a nontrivial exercise, it requires cooperation among sensor makers and machine manufacturers in order to work. Configurations, test and simulations all require knowledge and they require, at least today, people to create them.

The ability to install sensors, make sense or data and take action on it only represents the opening salvo for this problem space. To accurately forecast failure, head it off, and minimize impact on production, organizations will need to integrated operations data about the machine’s operating parameters and its history, corporate data about employees and expertise, environmental data like location, proximity to other equipment and safety data and as much original equipment manufacturing (OEM) information as can be had.
In order to narrow the maintenance window, AI will need to balance between operational need with maintenance, perhaps waiting until parts nearly fail before scheduling maintenance in a narrow window between shifts. The AI may also determine that the results of not maintaining a machine sooner than later would have a longer impact than shutting it down during prime production hours. When that window opens and for how long depends on the plethora of data sources and the values processed.
Perhaps someday an AI will exist that will configure the systems and hardware necessary to create a meaningful set of data from which predictions about the best time to perform maintenance can be derived. For today, the configuration of such a system requires people, and it requires specific knowledge and skills, many of which remain emergent.
Knowledge managers can help their organizations engage with the idea of the learning organization, with incremental innovation, with experimentation and with documentation. The goal to narrow the maintenance window will not arrive spontaneously from an algorithm but will arrive as the result of dozens of other processes that converge on that goal.
AR and maintenance
In the vision of technology-empowered maintenance, two other goals assert themselves. First, is the use of XR to bring all of the data to bear on the maintenance act. And second, to evolve that act so that it can be performed by robots rather than humans.
XR, the umbrella that includes augmented reality, virtual reality and mixed reality, literally adds dimension to the question of data. Even if an organization owns all of the maintenance manuals for a piece of equipment, and the manufacturer offers online coaching and video support, that data typically does not include coordinate data designed for augmented reality headsets.
In a typical AR scenario, the maintenance worker would be guided with instructions, coaching and special queues, like arrows, pointing toward which part to pick up, where to place it and how to secure it.
This means that an AI would likely be employed to identify parts, then part measurements would be used to calculate visual queues, along with process, to guide a workers hand to the right location—all on the fly as the system would not know exactly from which perspective the worker would be viewing the scene (which might change during the engagement).
Of course, there are ways to leap beyond the fumbling with new machines that include AR maintenance in their design. But with millions of active machines not just in manufacturing, but in plants and office buildings, under city streets and in millions of homes, the number of unique configurations likely outstrips humanities ability to create a solution that matches the vision for each instance. Most likely the biggest number of machines, in the most mission critical areas will find themselves targeted for investment. And again, people and knowledge, will be required to make the case for which equipment is worth investing in maintaining with high-order software and hardware investments, which should remain on preventative maintenance schedules until they reach end of life and which should best be replaced today by more sophisticated equipment with diagnostics and modern repair capabilities designed in.
Demands for a glimpse into the Blackbox
A primary goal of knowledge management is to make knowledge explicit. To have people write it down, or otherwise record it, so others can obtain, master, improve and pass along that knowledge.
The earliest AI fit well with knowledge management, as knowledge engineers worked with human experts to extract rules that would mimic the expert’s thinking process and make it available to others. Those “expert systems” could be asked why they arrived at a conclusion and their train of logic would be produced, showing what data they used to trigger which rules.
Expert systems existed in data-poor environments. Individual experts who understood, for instance, how to most effectively diagnose a problem and solve it, be it programming a production line, scheduling air traffic or pinpointing the best place to drill for oil, held the heuristics for these tasks closely. Their organizations worked with them to provide the best data, most of it analog, in order to inform their insights.
Most businesses now create data-rich environments. They often produce more data than they know what to do with. For those with mission-critical processes, they often turn to AI, or more aptly, machine learning algorithms, to not only mine their data for insights but to create operational systems that classify, predict, recommend or take action.

The most common form of this action comes in the displaying of advertising to people browsing on a website. Based on all of the data known about an individual consumer a targeted advertisement gets placed into a webpage. If you were to ask Google or Amazon why such an ad appeared, they would mimic what I just wrote. A complex set of indicators identified that ad as one the consumer was most likely to click on. While a person or team may know how an algorithm works, it cannot provide feedback on why it selected a particular ad for a specific consumer.
Modern AI or machine learning offers little or no insight into outcomes. The more data used to train the system, the less likely anyone could ever figure out how a particular input influenced a particular output.
While some very technical developments, like local interpretable model-agnostic explanations, (LIME), interpretability on top of inputs of the AI model like And-Or Graphs and Latent Explanations Neural Network Scoring (LENNS) may offer some insight into the Blackbox most of today’s systems don’t routinely offer explanations, and therefore aren’t very transparent. Data and AI scientists will continue to work to remediate this issue, but the impact and the result of surch research remains uncertain.
Knowledge managers can provide value to the AI teams by helping them understand how to document their intentions. Even if the machine learning decision processes remain impenetrable, system intent can be used to determine the general efficacy of the outcome.
AI is only as good as its data
A corollary to the Blackbox is the bias problem. Most AI researchers will assert that machine learning is unbiased. Unfortunately, this only holds true for the algorithms, not for the data. If a data model identifies racist data as a good fit for an output, and the algorithm trains on that model, then the system will reflect that bias.
The following table lists a number of trained machine learning applications that have exhibited bias, in some cases, extremely so. The recommendation above for mapping intent, while easy to say, may not be as easy to accomplish, because these systems exist within the biased context of those who develop them. Beyond simply documenting intent, the question must be asked if the intent itself creates a bias or if the only data available to drive a system toward the intended goal reflects bias.
In many cases, such as recommended ads based on purchase history, bias is part of the system. Amazon will likely never challenge my assumptions about the world by suggesting I buy something that people like me never buy to get me to try something new. And that reflects the limitation for this type of “intelligence.” The data is only good, at best, at predicting outcomes in a relatively steady state universe, and then, only at predicting things based on historical data. Any system that offers predictions about emergent or disruptive areas should be not be trusted.
The knowledge management spectrum
Whenever humans create a new device to see into inner space or further back in distance and time in the seeable universe, rules once thought established tend to fall away. The latest telescopic images and data, visual, thermal, infrared and other sources call into question what we know about physics writ large, particularly in the areas of dark matter and dark energy, two concepts that now purportedly represent the majority of the known universe. We do not know what makes up the majority of the universe and we do not know what is pushing it toward an ever speedier expansion. Of these ideas, the Nasa Science website says, “More is unknown than is known.”
The once solid models of physical structure have broken down from crystals and creatures to cells, to atoms and eventually to the components of proton and neutrons. The structure of microverse reveals an array of partials that make up the protons and neutrons known and up and down quarks.
Knowledge management offers an analog for this phenomenon in terms of storytelling and the character of knowledge. As we peer backward in time, we find large, deep structures that shape the human perception of creation, but examinations of those structures suggest disparities between various traditions, and science offers increasingly detailed factual refutation of religious and mythological traditions. The very idea of what is important to know gets called into question.
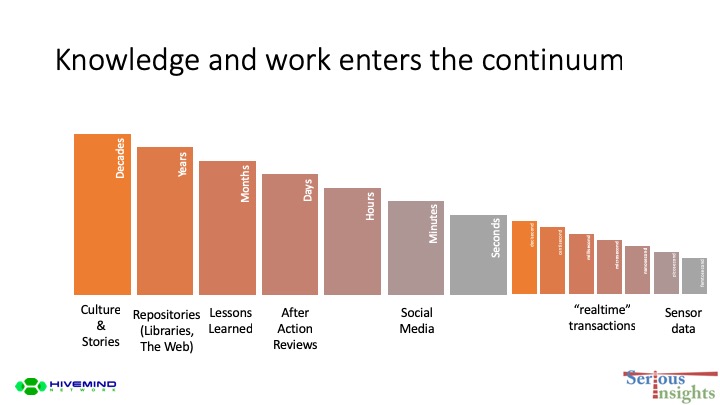
The cultures and stories that once proved the foundation of knowledge have been replaced by repositories, first in the form of libraries, and then in the form of digital artifacts, that track updated discoveries. In work environments, lessons learned track contextual discoveries that take place for months, while activities like After Action Reviews capture the stories around days, perhaps hours. As we look back in time from this moment, we face enormous amounts of information that will unlikely to contribut evenly to any one person’s knowledge or perspective on the world.
And as we go into the infinitesimal realm of real-world data, we find, like the atom, that decisions break down into the data that drives them, and that the idea of time as something of a human scale breaks down. Knowledge at this level becomes not just enormous, but unfathomable. Has humans we cannot know all of these details, even computers are not capable of modeling more than slices through the data. We will never know all of these details, but they inform our interactions as computers and the systems that run on them seek patterns and make predictions and recommendations where our need intersects currently available analysis. This data informs what systems know about us, even if we are unaware, and cannot become aware of that knowledge.
The Internet of Things creates massive amounts of data about massive amounts of things being monitored or controlled. And with wearable devices, we become part of that data stream as heart rates, exercise and breathing patterns find their way to the cloud. Some of this data only means something at the time it is being acted upon, and may never mean anything else again. Systems will discard what they cannot use and it will likely become irretrievable.
AI, however, has the ability to act upon this data more regularly, more consistently and with greater rigor than humans. Even in its currently narrow applications, AI will learn more about its domains than we ever will, in a way that it will be unable to transmit back even as it acts on what it knows.
Like time zero of creation, we are developing technologies that while we may remain in control today, we will experience a diminishing ability to understand the components and what drives them. We will likely lose our ability at some point in the future to explain the outcomes of our investments.
What can knowledge managers do?
Knowledge managers, like scientists, have to deal not with what they wish or hope to have, but what they do have. When knowledge was about stories, about capturing knowledge in rules and developing better ways to share knowledge, the role of the knowledge manager was clear: help the organizations become better by remembering what it knows and leveraging that knowledge for improvement.
Today, knowledge management requires a different set of skills, perhaps even a different set of objectives.
First, knowledge managers should help organizations going at breakneck speed into the world of AI to understand the intention of the systems being developed, and understand how, at least conceptually, those systems see the world. The biggest threat from AI is not that it awakens with a goal to hurt humans, but that humans fail to consider all the parameters in play and release an AI that does exactly what it is instructed to do, completely unaware of the unintended consequences of its creators—perhaps to the point of human jeopardy.
Second, knowledge managers need to help organizations understand and design for the complexity of knowing in the age of AI, IoT and XR. The benefits of these technologies only occur when they reflect purposeful curation of their inputs. Knowledge managers can help test for bias and determine what questions to ask about assumptions, intent and outcomes.
Third, knowledge managers can help organizations sense shifts in underlying assumptions so that they update or retire systems of questionable relevance before they make mistakes, mistakes that perhaps create safety issues for people.
Forth, on the practical side, knowledge managers can help organizations think about sensors and how best to deploy them to provide data that yields insight and reduces damage and threat, and what kinds of interpretations of that data will provide value. They can also help define the relationship between humans as sensors of change, and how increased visibility helps humans better understand the world around them.
Fifth, knowledge managers can help organization step back, and working with human resources, define the requisite skills, as they emerge and evolve, that will help ensure the ethical implementation of AI and IoT.
Lastly, knowledge managers can become the conscience of their organizations, seeking to ensure the privacy and safety of customers and their data by asking what knowledge is actually required to provide value, to drive innovation, to service needs—and what data may simply exploit, perhaps harm customers, the organization or society as a whole.
Knowledge managers, more than anything, need to help their organizations do what the discipline has suggested from its inception: pay better attention to the world around it, both digital and analog.


Learn more about data, information, knowledge and wisdom in this Serious Insights Post:
Leave a Reply